EU Open Research Repository
by
![]() Lars Holm Nielsen,
on March 20, 2024
Lars Holm Nielsen,
on March 20, 2024
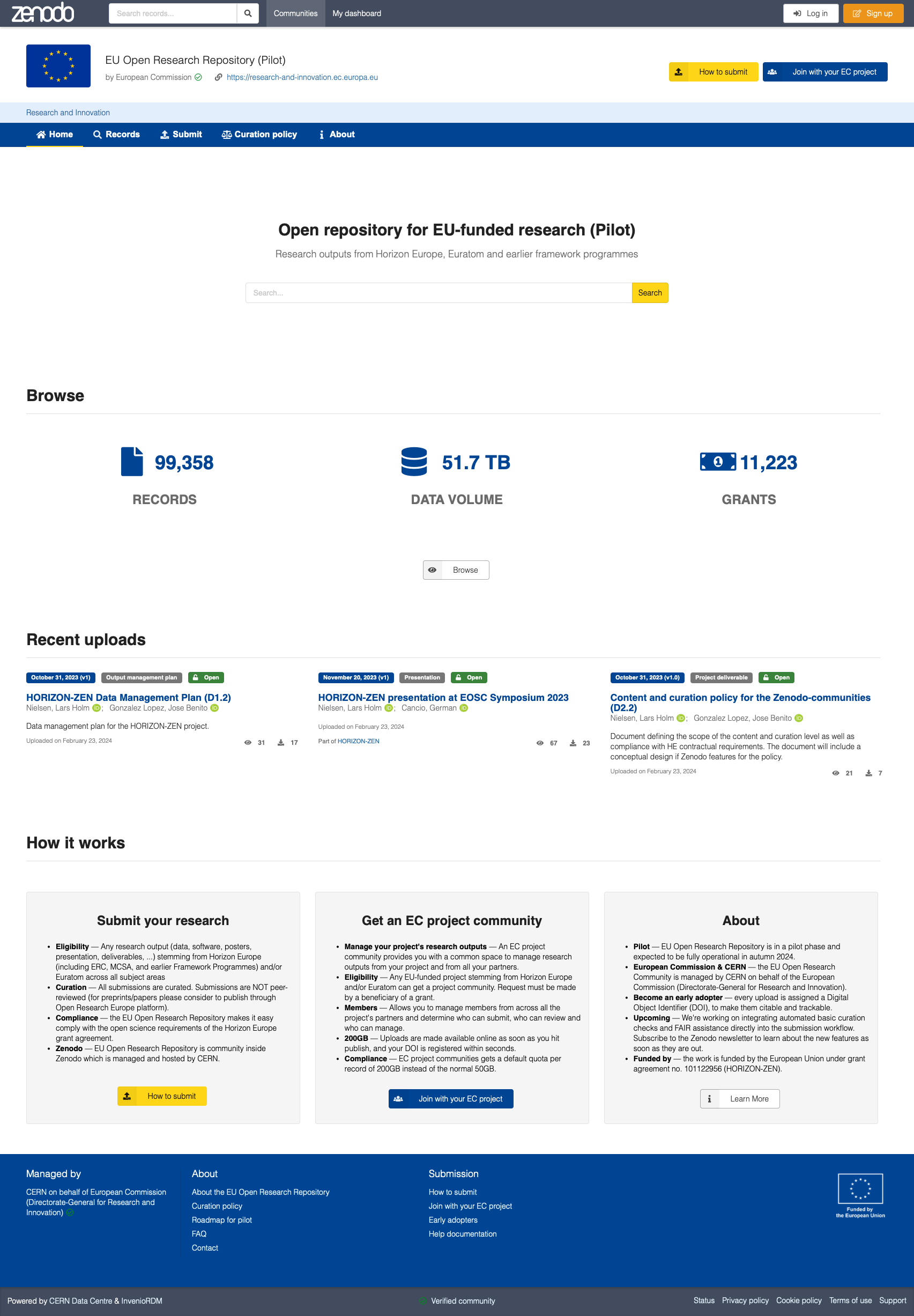
The European Commission and CERN are today launching a pilot of the new EU Open Research Repository that welcomes research outputs (data, software, posters, presentation, project deliverables) stemming from one of EU’s research and innovation funding programmes such as Horizon Europe and Euratom.
Supporting EU Open Science policy
The EU has increasingly supported the implementation of the Open Science policy in successive Research and Innovation Framework Programmes, starting from the Open Access pilot in FP7, adding Open Data provisions in Horizon 2020, and laying down in Horizon Europe a set of provisions for open science practices such as open access to scientific publications, open access to research data and responsible management of research data, notably through the mainstreaming of data management plans and in line with the FAIR principles. This evolution has been accompanied by several EU-funded actions to support beneficiaries to better manage their research outputs and to facilitate the implementation of the programme provisions. This has notably included support to the creation of Zenodo, a general-purpose open repository operated by CERN, allowing researchers to deposit research papers, data sets, research software, reports, and any other research related digital outputs.
The new EU Open Research Repository, a Zenodo-community, capitalizes on past investments made in Zenodo and helps EU programme beneficiaries comply with the new FAIR and open science requirements, by implementing an easy go-to solution in Zenodo for beneficiaries to make data FAIR in practice. The repository is managed by CERN on behalf of the European Commission.
Pilot
Currently in its pilot phase and set to be fully operational during autumn 2024, the EU Open Research Repository is constantly evolving. Efforts are committed to integrating cutting-edge features, including assisted curation and FAIR (Findable, Accessible, Interoperable, and Reusable) assistance, to further support the research community. The goal is to provide researchers with a simple goto solution for making their publicly funded research open and as FAIR as possible.
Supporting EU research projects
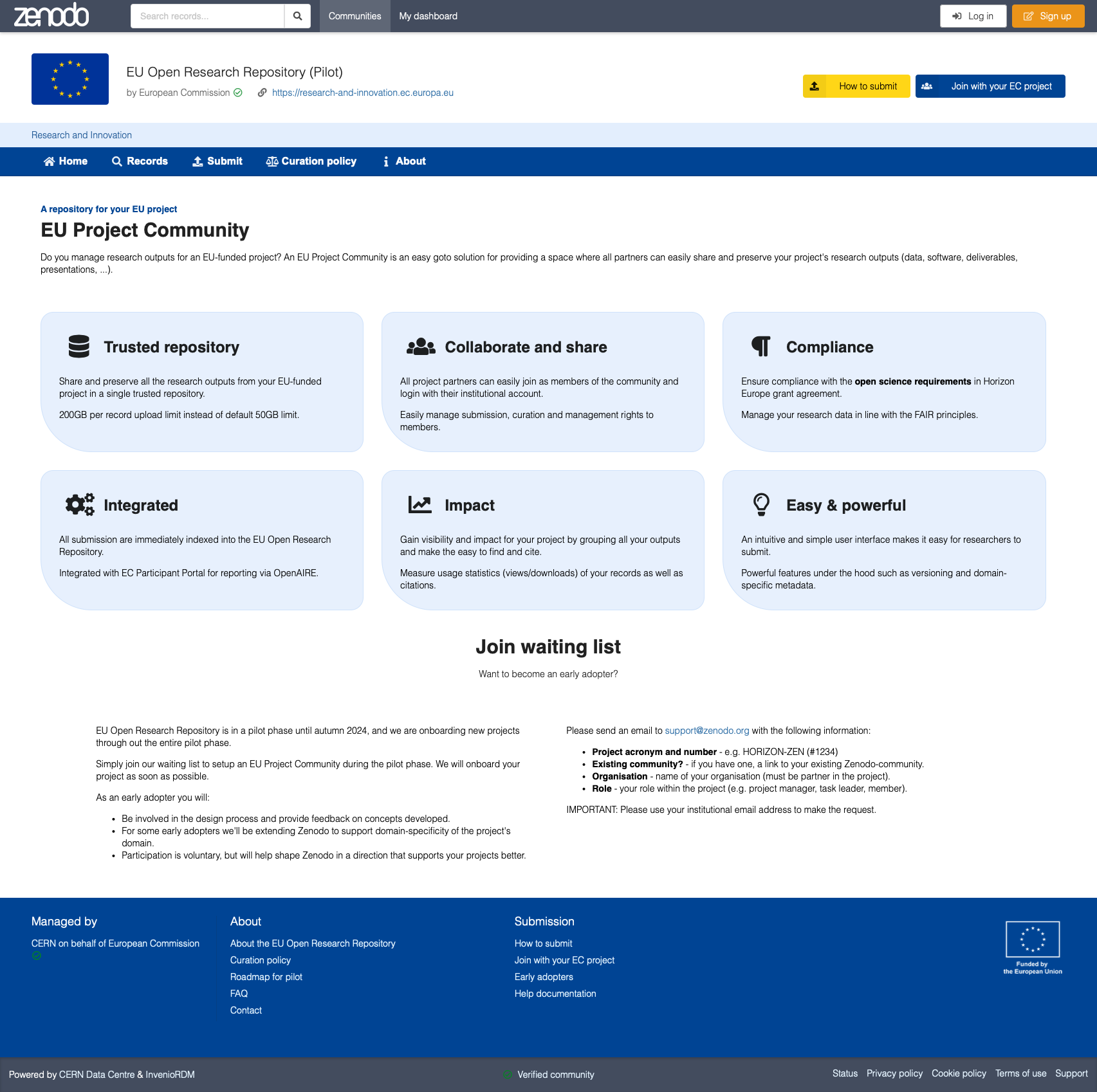
Today, more than 500 EU-funded research projects already have a Zenodo-community where they share their research outputs. The EU Open Research Repository will index all these and future project communities under a single umbrella and provide them with enhanced features to enable all project partners to easily share the project’s research outputs. Zenodo has since its launch more than 10 years ago supported linking research outputs with the EU grant that funded the work, which means that Zenodo today hosts more than 100,000 research outputs from more than 11,000 different grants.
Several early adopter projects from different domains (BY-COVID, FAIR-IMPACT, FAIRplus, GDI, iMagine, interTwin, RESILIENCE, SERPENTINE) are collaborating to help provide feedback on the features developed for the new repository. Other projects interested in adopting the new features can sign up for free and will be onboarded as soon as possible through out the pilot phase.
Open Research Europe (ORE)
The EU Open Research Repository serves as a complementary platform to the Open Research Europe (ORE) publishing platform. Open Research Europe focuses on providing a publishing venue for peer-reviewed articles, ensuring that research meets rigorous academic standards. The EU Open Research Repository provides a space for all the other research outputs including data sets, software, posters, and presentations that are out of scope for ORE. This holistic approach enables researchers to not only publish their findings but also share the underlying data and materials that support their work, fostering transparency and reproducibility in the scientific process.
Funding
The EU Open Research Repository is funded by the European Union under grant agreement no. 101122956 (HORIZON-ZEN).
You can learn more about the HORIZON-ZEN project on https://about.zenodo.org/projects/horizon-zen/
Zenodo Newsletter March 2024
by
![]() Lars Holm Nielsen,
on March 19, 2024
Lars Holm Nielsen,
on March 19, 2024
News
Pilot of new EU Open Research Repository launched
The European Commission and CERN today initiated a pilot for the new EU Open Research Repository, which is designed to include research outputs—such as data, software, posters, presentations, and project deliverables—originating from one of the EU’s research and innovation funding programs, including Horizon Europe and Euratom.
Documentation updates: FAQ
We've reorganized and updated our Frequently Asked Questions (FAQ) documentation to make it more easily searchable. Check out the updated FAQ at https://support.zenodo.org/help/ and share your feedback with us. Don't hesitate to let us know If there's any question you'd like answered there.
See:
Domain-specific fields (Biodiversity)
We've made new domain-specific fields available in the upload form. These fields have long been available in our API as part of our collaboration with the Biodiversity Literature Repository, but only recently have we made them generally available in the upload form for everyone to use. The fields allow you to add and search DarwinCore metadata terms on Zenodo, so you can e.g. search for records related to a specific museum collection via the collection code field. The work is part of the BICIKL and Arcadia projects.
Integration with Software Heritage (in testing) and new software fields
We have implemented an integration between Zenodo and Software Heritage which is currently undergoing testing before being launched. Among the improvements are also 3 new software specific fields which has already been made available on Zenodo: repository url, programming language, development status (see the software section in the upload form). These fields were added to align with the Codemeta standard. The developments are part of the FAIRCORE4EOSC project.
Short updates
Webinars/events
- March 25th (webinar): OMF ModelShare on preserving and publishing computational models (Zenodo, PLOS Biology and OMF)
- Jun 3-6 (conference): Open Repositories 2024 with InvenioRDM workshop
Did you know?
- Zenodo-communities can have multiple members and curators of a community can edit metadata of records in their community.
Zenodo upgrade issues
by
![]() Lars Holm Nielsen,
on October 19, 2023
Lars Holm Nielsen,
on October 19, 2023
As many of you noticed, the Zenodo upgrade last Friday didn’t go as smoothly as hoped. Afterwards Zenodo was sluggish and file uploads were painfully slow, some features didn’t quite work as expected. We’ve been working flat-out behind the scenes to steer Zenodo out of these stormy waters. We’d like to keep you updated on the issues we had, what we solved so far, and what we are still working on.
The upgrade involved orchestration of three components; Zenodo’s refactored software platform, the data, and the technical infrastructure:
- We’d developed the refactored software platform in collaboration with partners around the world, 6 of which already had production instances running on the new code (*), giving confidence, but we none the less tested extensively on the full feature set used on Zenodo. We’d been smoothing off rough edges, and were prepared to rapidly address more that you might discover after release.
- As custodians of your data, for months we meticulously exercised the process of migration to the new system to ensure every bit made it reliably, and also have multiple backups as safety and for verification.
- We’d revamped the technical infrastructure to better serve the continued scaling demanded by Zenodo’s ceaseless growth, by using components heavily used in our other front-line services, which none the less we also stress/performance tested in the preparations.
The main issue after the upgrade was immediately evident that file upload/download was painfully slow (1GB file taking 1 hour instead of 20 seconds). We worked the weekend to finally discover that circumventing the front-facing load balancer alleviated the problem, and on removing it we restored Zenodo’s expected data performance (the root cause is still being investigated by the infrastructure experts).
We also had indexing issues with records which meant they didn't show up despite the data having been migrated, and despite having had successful test migration runs. We have almost finished to resolve this issue and expect the main issues to have been solved by Monday.
We want to thank you for all the incredible support and understanding that we have been receiving even under such difficulties. We’ve not ignored the functionality hiccups you’ve been reporting, we already solved some in parallel to the performance debugging. Please rest assured that we continue to work relentlessly to address all your support requests and feedback, and to address all outstanding issues in a timely manner to help you publish/access your content.
We apologise for all the inconvenience it has caused. We hope once we're over the hiccups the new Zenodo will serve you and your communities well!
Final lesson learnt: Friday 13th[**] might not have been a good day for a major release after all.
(*)
- Northwestern Uni: https://prism.northwestern.edu/
- NYU: https://ultraviolet.library.nyu.edu/
- GEO Knowledge Hub: https://gkhub.earthobservations.org/
- Caltech Library: https://data.caltech.edu/
- TUGraz: https://repository.tugraz.at/
- TUWien: https://researchdata.tuwien.ac.at/
(**) We chose a Friday as Zenodo has considerable less traffic during weekends and thus as risk mitigation measure we would impact less users if there were problems (as there unfortunately turned out to be).