Extended grant support, ORCID and language field.
by
![]() Krzysztof Nowak,
on October 10, 2017
Krzysztof Nowak,
on October 10, 2017
Today, we are introducing three additions to Zenodo:
- Extended grant support
- Language field
- ORCID for authors
Extended grant support (powered by OpenAIRE)
We are expanding our grants database with over 620,000 grants from 8 new funders such as the National Science Foundation (US) and Wellcome Trust (UK) - all thanks to OpenAIRE's ever growing grants database.
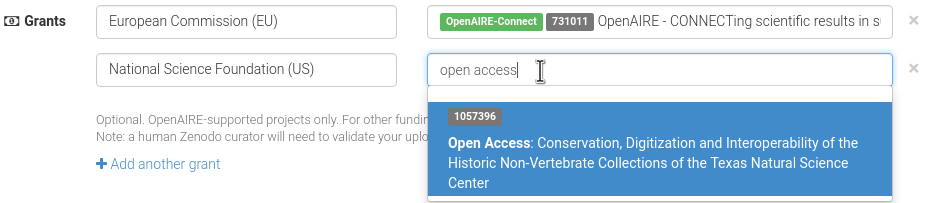
So far we have only been supporting grants from the European Commission (FP7 and Horizon 2020). Today our dataset has grown and contains grants from the following funders:
- National Science Foundation (USA) - 497646 grants
- European Commission (EU) - 39409 grants
- Foundation for Science and Technology (Portugal) - 37277 grants
- National Health and Medical Research Council (Australia) - 24354 grants
- Netherlands Organisation for Scientific Research (The Netherlands) - 24180 grants
- Australian Research Council (Australia) - 23011 grants
- Wellcome Trust (United Kingdom) - 12196 grants
- Ministry of Science and Education (Croatia) - 2120 grants
- Ministry of Education, Science and Technological Development (Serbia) - 777 grants
which means that our grants database grew from nearly 40,000 to over 660,000 grants! We wouldn't have been able to do that if it wasn't for the OpenAIRE team and their hard work in collecting, maintaining and distributing the grants database for the benefit of Open Science!
Language field
Today we are also adding a new language field to our metadata, which allows you to record the primary language of an upload. You can select the language in the upload form simply by starting to type the English name, a 2-letter or a 3-letter ISO 639 code:
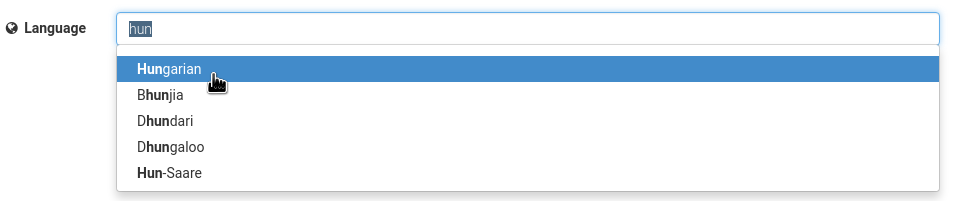
The new language field supports all languages defined in ISO 639-3, which in total defines 436 individual and macro-languages. For the full reference of language codes see the Library of Congress ISO 639 Language List.
What if my record contains more than one language?
The field is used to specify the primary language of the resource, hence if, e.g., a thesis is written in Danish and has an English abstract, then the primary language is Danish. Similarly, the primary language of a paper written in English, which is on the topic of Greek linguistics, thus containing a lot of text in Greek, is English.
There are always cases where it is not possible to clearly determine the primary language, for example for a dataset containing the mapping between common Polish and French phrases. In those special cases you can always use ISO 639-3 code mul (Multiple Languages).
ORCID for authors
Last but not least, you can now include an author's ORCID under the Authors section of the metadata on the deposit web interface.
