Fighting spam - safe listing
by
![]() Lars Holm Nielsen,
on July 13, 2022
Lars Holm Nielsen,
on July 13, 2022
Zenodo's vision is to enable researchers around the world to share and preserve any research output from any discipline via a seamless user experience. The same features that make it easy for any researcher to share and preserve their research, as a side effect also make it easy for spammers to misuse our service.
As Zenodo grew in popularity, our spam problem grew as well. We firmly believe in the need to make sharing and preserving research data as easy as possible, and thus we have always opted against introducing factors blocking researchers' ability to share and preserve their research instantly. So far, we have been fighting spammers with automated classification systems and manual reviews, yet with every counter-measure we've taken, spammers have adapted their methods.
Today, we're introducing yet another counter-measure to fight spammers. Content from new users will, as of today, be ranked below content from safelisted users. This means that spam will be less visible in all search results, allowing our automated classification system more time to catch the spam. In addition, we will be introducing a human review of all new users uploading content to Zenodo that will allow us to safelist new users and catch spammers. The human review is in progress of being introduced as part of our support operations, and we will also go through the backlog of existing users to safelist them. We have seeded the initial safelist with all users who logged in via ORCiD and GitHub, and users with existing uploads accepted in communities.
All in all, if you're an existing Zenodo user and didn't login via ORCiD or GitHub, or had any of your uploads accepted in a community, your records will appear at the bottom of search results. We will be working on safelisting all existing users as fast as possible.
If you're a new Zenodo user, your uploads will also appear at the bottom of search results until our manual review has safelisted you. We plan safelisting new users at least once a day during business days, but until we have worked through the backlog of existing users there might be a longer delay.
The new feature in no way limits you ability to share and preserve research results. You can still upload your data, software and publications to Zenodo, and get a DOI instantly. The new measures only make sure that spam that makes it past our automated classification system is much less visible in search results, until a human review can catch the spammer.
Zenodo Enables a New Workflow for Collectors of Natural History Specimens
by
![]() David P. Shorthouse,
David P. Shorthouse,
![]() Dr. Zoë Goodwin,
Dr. Zoë Goodwin,
![]() K. Samanta Orellana,
on June 27, 2022
K. Samanta Orellana,
on June 27, 2022
![]()
Bionomia, launched August 2018 with the aim of linking natural history specimen records to people who collected them and/or identified them to species. The two main goals are to:
(1) give credit to and improve the visibility of people who have contributed to the world’s natural history collections (see Thessen et al., 2019; McDade et al., 2011); and,
(2) encourage natural history collections data managers to incorporate these new digital annotations into their source data warehouses, which completes a round-trip of high-quality, curated annotations.
Zenodo is a key piece of infrastructure to help realize the first goal, especially for graduate students and early career researchers who desire a breadth of ways to illustrate their expertise and impact.
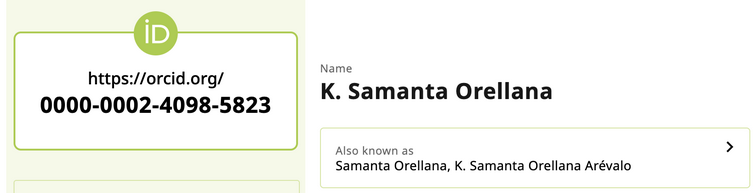
Bionomia uses data that is produced by the world’s natural history collections and subsequently shared with the Global Biodiversity Information Facility (GBIF). Linking specimen records to people in this data is however challenging because people names are typically expressed as free-text with considerable variability in the ordering of the parts of names, abbreviations, and according to local cultural practices in the used data exchange standard maintained by Biodiversity Information Standards (TDWG). Through Bionomia, authenticated users actively disambiguate these text-based “agent strings” as they are commonly called, into Uniform Resource Identifiers (URIs) from Wikidata or ORCID as declarations of unequivocal person identity. Thus, free-text strings for people are enhanced to become uniquely identifiable and are thus better participants in the exchange of data according to the FAIR principles (Wilkinson et al., 2016).
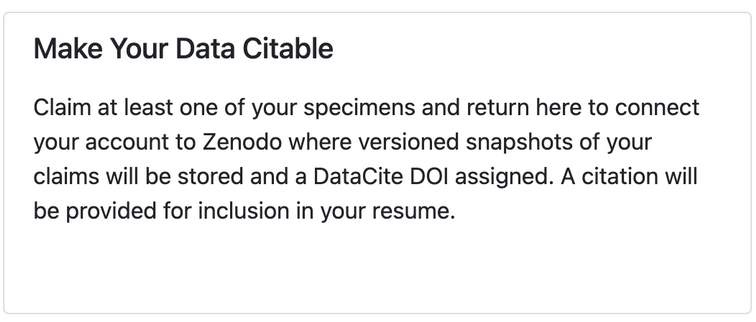
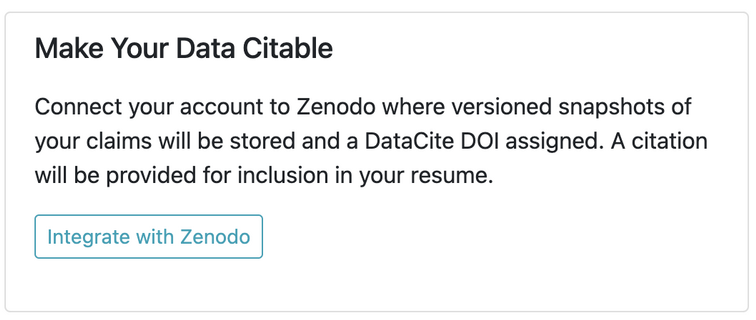
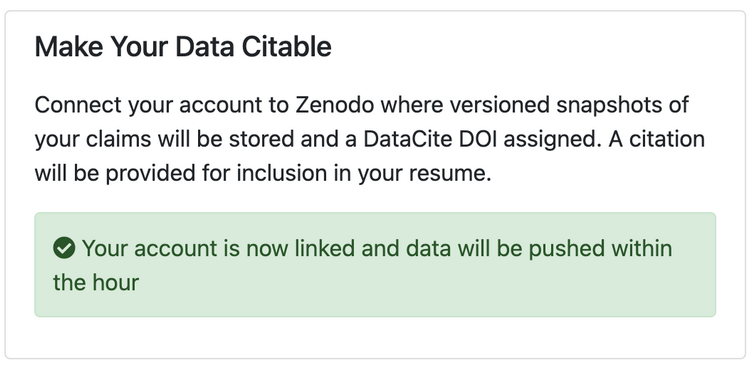
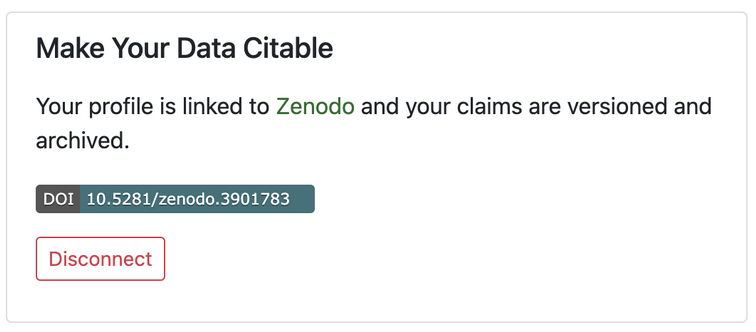
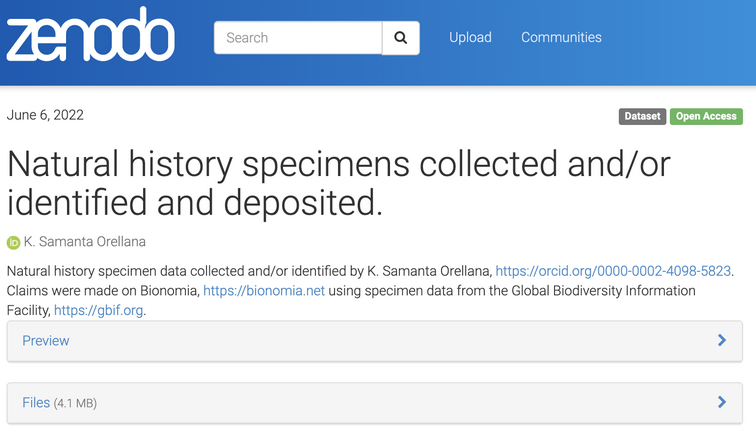
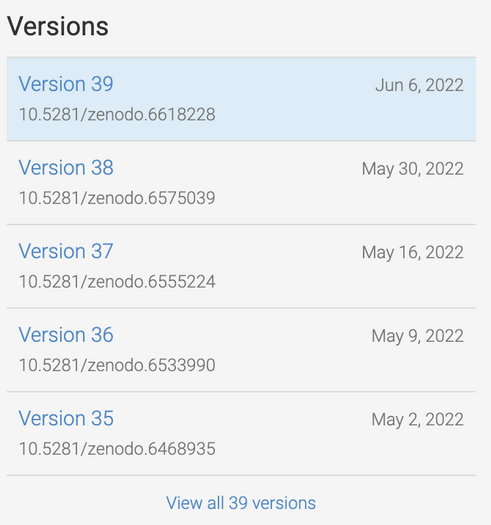
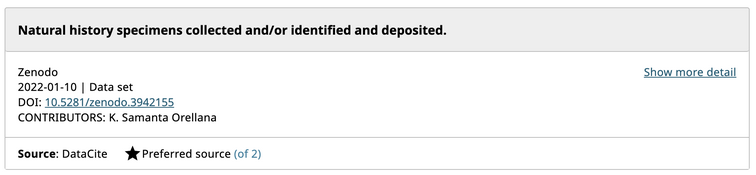
When a user first logs in to Bionomia via OAuth using their ORCID credentials, they are presented with an interface to claim the records of natural history specimens they collected or identified. Over 175M records are downloaded and refreshed from GBIF into Bionomia every few weeks, then processed and pre-indexed for a pleasing experience, which would ordinarily have been a daunting task for any user. The reason for this refresh cycle is to keep pace with the continuous activities that occur upstream in the world’s museums and collections in which researchers deposit their physical specimens. Each user has a “Settings & Integrations” section in their account in Bionomia where they have the option to archive their data to Zenodo. Behind the scenes, Bionomia makes use of Zenodo’s well-documented REST API for users to authenticate using OAuth – most often using their ORCID credentials once again – and then auto-deposits versioned archives of users’ claimed specimen records as both csv and JSON-LD files. The mechanics of this interaction is made seamless for users (Figures 1–4); they complete the process with a few clicks and no typing or form submission is required of them. Within moments, they have a new freely accessible (Creative Commons Zero v1.0 Universal) entry in Zenodo as a resource type “dataset” along with their ORCID ID clearly indicated, a handful of keywords, a formatted description, a title, a referenceable citation (Figures 5 & 6), and a DataCite DOI. Whenever specimen records are newly attributed to or claimed by users who have enabled this integration between Bionomia and Zenodo, their datasets are automatically constructed anew, pushed to Zenodo, and new versions appear (Figure 7). If a user additionally configures their ORCID profile to accept DataCite as a trusted party, their new dataset entry appears in ORCID soon afterward alongside their publications and affiliations (Figure 8).
To date, 84 users of Bionomia have integrated their account with Zenodo and are collectively archiving 552,659 specimen records. While this may seem like a small number of active integrations, this is a valuable service for each of them. Many researchers were newly introduced to this novel workflow – archiving specimen-based data is an uncommon practice in our domain – and are now appreciative of Zenodo’s mission, user-friendly design, flexibility, and openness. Why not join this growing open science movement, by claiming your specimen data?
Testimonial by Dr. Zoë Goodwin
As a tropical botanist, a lot of my effort goes into the fundamental aspects of natural history data: the collection, identification and naming of plant specimens. Without these actions we can have no understanding of the natural world around us. However, until now it has been virtually impossible to keep track of these actions, claim them as work and then see how my particular efforts have contributed to other scientists’ research. By using Bionomia to claim the specimens that I have collected and identified in GBIF, for the first-time others can see what I have done and see how I have contributed to our understanding of the natural world. Then, importantly as an early career researcher I can include all this information as a citation & DOI using Zenodo in my CV or on my personal webpage.
Goodwin, Zoë. 2022. Natural history specimens collected and/or identified and deposited. [Data set]. Zenodo. https://doi.org/10.5281/zenodo.3581428
Testimonial by K. Samanta Orellana
When I started studying insects in Central America, I had the opportunity to collect, process, and identify thousands of specimens in different entomological collections. However, I didn’t have the means or even know how to digitize and mobilize collection data and many of these activities went unnoticed. It wasn’t until I started my research as a PhD student in the US, that I was able to learn about the digitization workflows and the importance of sharing data in global aggregators such as GBIF. At the same time, I was able to learn about Bionomia and I was instantly engaged. Being able to see the details about my work in collections, and see how the specimens are connected to other collectors or taxonomists, became a strong motivation to continue digitizing and sharing data. Moreover, the ability to compile this information via Zenodo and make it citable has been a great way to make my contributions visible through my ORCID researcher profile, also allowing me to keep records of the progress made during my doctoral program.
Orellana, K. Samanta. 2022. Natural history specimens collected and/or identified and deposited. [Data set]. Zenodo. https://doi.org/10.5281/zenodo.3942155

References
McDade, L.A., D.R. Maddison, R. Guralnick, H.A. Piwowar, M.L. Jameson, K.M. Helgen, P.S. Herendeen, A. Hill, and M.L. Vis. 2011. Biology needs a modern assessment system for professional productivity. BioScience 61(8): 619–625. https://doi.org/10.1525/bio.2011.61.8.8
Thessen, A.E., M. Woodburn, D. Koureas, D. Paul, M. Conlon, D.P. Shorthouse and S. Ramdeen. 2019. Proper attribution for curation and maintenance of research collections: Metadata recommendations of the RDA/TDWG Working Group. Data Science Journal 18(1): 54. http://doi.org/10.5334/dsj-2019-054
Wilkinson, M., M. Dumontier, I. Aalbersberg et al. 2016. The FAIR Guiding Principles for scientific data management and stewardship. Sci Data 3: 160018. https://doi.org/10.1038/sdata.2016.18
Hardening our service
by
![]() Alex Ioannidis,
on December 7, 2021
Alex Ioannidis,
on December 7, 2021
We’ve talked in the past about the challenges of running a service at the scale of Zenodo in the inhospitable environment of the modern internet. Over the past couple of years, we have experienced an exponential increase in our users, content, and traffic… and we couldn’t be happier that Zenodo is proving useful in so many different ways! For Open Science to flourish, researchers should feel empowered to share their data, software, and every part of their journey of publishing their work. We are proud to have done our part in lowering the barrier to share and preserve.
This year we crossed the threshold of 2 million records, we are closing in on storing our first PetaByte of data, and we’ve reached 15 million annual visits. To keep up with these challenging requirements, our team put their heads together with our colleagues here at the CERN Data Center. Their long-running expertise in handling PBs of data generated from the CERN experiments is one of the reasons why we can offer a reliable service to the world in the first place. Over the past year, we have tweaked and optimized our infrastructure to help solve a variety of scaling and performance issues that we’ve faced.
Improved file serving
One of the main culprits for our performance bottlenecks was the way we served files. Our web application was doing all the heavy-lifting, while the number of concurrent connections we needed to serve was increasing. The solution was simple: leave the heavy-lifting to the pros 💪. With the help of our CERN storage team, we now have a dedicated setup for offloading file downloads directly to our EOS storage cluster.
This change also came with a bonus side-effect: Zenodo file downloads now support HTTP Range requests! This means resumable file downloads, as well as the unlocking the possibility for a wide range of applications which depend on accessing small parts of large files (e.g. Cloud Optimized GeoTIFF, Zarr).
Dedicated space for crawlers and bots
Given our high content intake of almost 10k records on a weekly basis, it was natural that web crawlers and indexers had a tough time going through everything without stealing resources from normal users. There are conventions that instruct crawlers to slow down, but unfortunately, not all crawlers respect them. To minimize the impact crawlers have on the rest of the users, we’ve put up a dedicated space that serves them in a machine-friendly fashion. That means that regular users get a performant and snappy experience while browsing our pages, while crawlers still get to index Zenodo at their own pace.
Towards a stable future
This is of course not the end of the story. We expect Zenodo to continue growing at the same rate and we have many plans to further stabilize and scale our infrastructure. We have closely monitored our database and search cluster performance, and identified points of improvement based on industry best practices. We’re also eager to explore ways to provide cached versions of our pages.
Last, but not least, our efforts in building and rebasing Zenodo on top of InvenioRDM, a turn-key solution for digital repositories, come in the form of a bottom-to-top revamp of our software stack, based on the same pillars that made Zenodo what it is today: a resilient, top-of-the-class user experience, and scalable platform at the service of Open Science.