Major database incident
by
![]() Lars Holm Nielsen,
on August 21, 2018
Lars Holm Nielsen,
on August 21, 2018
What happened?
On Friday August 17 at 11:45 UTC the Zenodo database crashed because of a full volume on the database server. During auto-restart the database crashed again corrupting tables, which proved to be extremely difficult to recover from. It took three senior engineers, working round the clock, close to 2 days and 12 hours to bring Zenodo back online eventually on Sunday August 19 at 23:30 UTC.
How did it happen?
The root cause was an import of 2 million new grants to our grants database. This generated a very high insertion rate to our database. The database server has built-in protective mechanisms that automatically extend the disk volumes in case they approach being full. Exceptionally, due to the high insertion rate, the mechanisms did not fire fast enough. The full disk caused the database to crash after which it automatically restarted and tried to recover. Exceptionally, during the recovery phase, the database crashed again causing corruption to parts of the database.
Is it fixed?
Through hours of manual reconstruction work we have recovered the entire database until 20 minutes before the crash. We are still working on recovering the remaining 20 minutes from other sources. We have good hope to have finished recovery of the full database by the end of the week.
Is my record affected?
Only a handful of records submitted in the 20 minutes before the crash are affected. We have temporarily disabled these records until we have managed to thoroughly verify their integrity. If your record has been disabled, you’ll see a page similar to this one https://zenodo.org/record/1346821.
Why so long downtime?
Our prime concern is to avoid data loss, so we chose the harder, longer path to recover in order to minimise data loss rather than maximise uptime. We currently backup our entire database every 12 hours to disk and every week to tape. The latest backup prior to the incident was at 05:00 UTC. Thus using this backup would have meant more than 6 hours of data loss from the database. To avoid data loss, we therefore decided instead to repair the corrupted parts of the database, thus causing significantly longer downtime than if we had restored a backup. The repairing was possible because we could re-validate the database against our search index and web server access logs.
Were my files at risk?
No, the files (the payload of every record) are stored outside the database which only stores the metadata of the records. These files are stored in multiple copies on multiples servers before a new record is completed in the database. However accessing and serving the files requires the database record that points to them. In addition, we write submission information packages (SIPs) to disk which contain both the metadata and uploaded files, however these SIPs are not written to disk immediately, and thus don’t help recover data close to a crash.
What did we learn?
It is said that every challenge faced makes us stronger! Even though we have numerous protection and self-healing mechanisms at each level of the stack they were not enough, and did not protect against combinatorial failures. We are thus taking this incident very seriously and thoroughly investigating what happened and what can be improved to avoid even more failure modes and to make recovery quicker. One track we are looking at is replica configurations that would isolate crash corruptions to one node.
Usage statistics launched!
by
![]() Alex Ioannidis,
on July 18, 2018
Alex Ioannidis,
on July 18, 2018
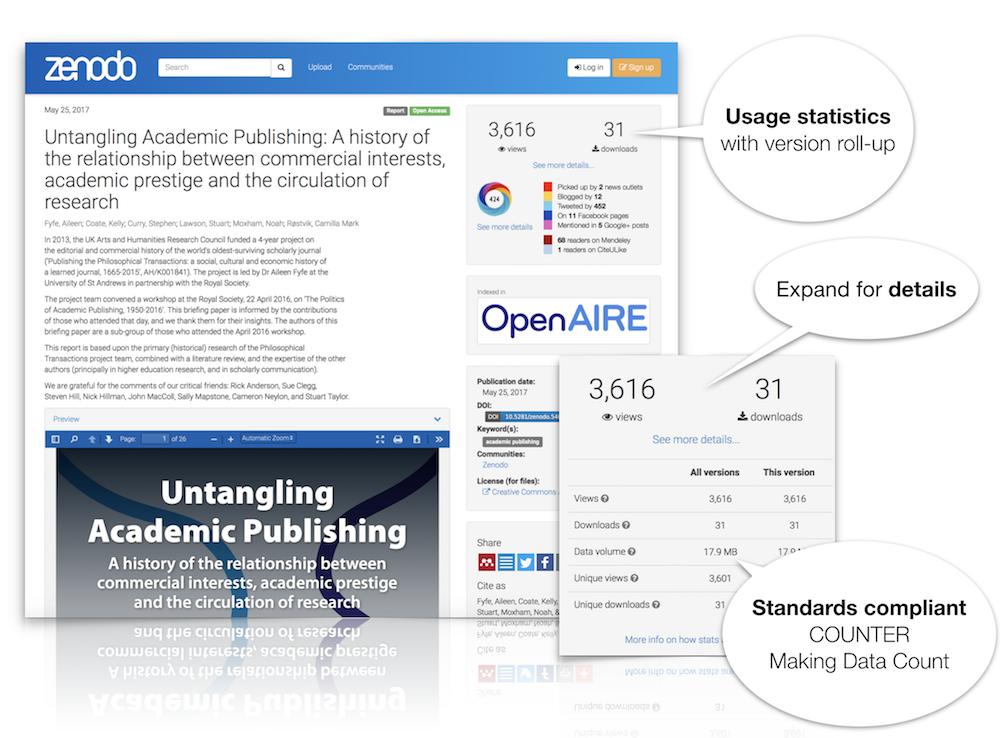
We are happy to announce the launch of usage statistics on Zenodo. From today, you will find the number of views and downloads on record pages, and you can sort search results by most viewed. By default we roll-up usage statistics for all versions of a record. However, it is also possible to see detailed usage statistics for the specific version of a record.
Privacy and standards compliant
We strongly believe in user’s right to privacy, thus we have spend a lot of time to design our system to ensure all tracking is completely anonymized. Our usage statistics is further tracked according to industry standards such as the COUNTER Code of Practice as well as the Code of Practice for Research Data Usage Metrics and thus allows you to compare metrics from Zenodo with other compliant repositories. You can read much more about this, and exactly how and what we track in our FAQ.
The launch today, also only marks the beginning. We will later also be adding usage statistics e.g for your communities, so stay tuned!
If you have any questions or feedback (positive and negative) don’t hesitate to get in touch with us.
Zenodo and General Data Protection Regulation (GDPR)
by
![]() Lars Holm Nielsen,
on May 25, 2018
Lars Holm Nielsen,
on May 25, 2018
The General Data Protection Regulation (GDPR) takes effect in Europe on May 25, 2018. The GDPR provides a legal framework for the collection and processing personal information for people in the European Union (EU). The goal is to provide individuals with more control over their personal data.
Zenodo is hosted at CERN, which is an Inter-Governmental Organization (IGO), with its seat in Switzerland. Despite the fact that this means CERN has a special status, we are striving for the same high standards of data protection afforded by GDPR. In fact the GPDR has provisions covering data transfer to/from IGOs and the concept of "adequate protection", i.e. qualified as equivalent. This is what we will offer in Zenodo.
CERN takes seriously the privacy and protection of personal information, and have appointed a Data Protection Officer and, as mentioned above, are working on policies to ensure CERN is compatible with GDPR.
Specifically on Zenodo, we are taking the following actions:
- Review and update our Privacy Policy to provide specific information about what data we collect, how we use it and when we delete it.
- Assess our collecting of personal information.
- Evaluate and ensure that any third-party tools and services are GDPR compatible.
If you wish to review the personally identifiable information about you maintained by Zenodo, or would like your information removed from our records, you may contact us anytime.
More information: